

Разработка безопасных и доступных транзакций на Efinity приведет к созданию более быстрых реестров и ускорит демократизацию таких прорывных технологий, как NFT.
Одна из самых больших головных болей разработчика блокчейна заключается в том, как снизить сборы как можно ниже, не жертвуя безопасностью или скоростью.
В Enjin мы рассматриваем такие препятствия как возможность внедрять инновации, расширять границы и адаптировать наши решения к меняющимся потребностям наших пользователей.
В этой статье я опишу одну из основных оптимизаций, которые мы применили к Efinity, что значительно улучшит опыт наших разработчиков и пользователей игр:
- Чеканка огромного количества невзаимозаменяемых токенов (NFT)
- Пакетные переводы огромного количества NFT
Не пропустите окончательные контрольные показатели в конце статьи!
Оптимизация транзакций NFT
Проблема: Пропускная способность ввода-вывода
Efinity разработан с использованием субстрата (от Polkadot) и будет развернут в виде пара-потока. В этой экосистеме доступ к хранилищу (чтение или запись состояния блокчейна) имеет решающее значение, когда вы оцениваете транзакцию (внешнюю) вашей среды выполнения.
Цель здесь состоит в том, чтобы максимально сократить количество операций ввода-вывода в хранилище, что будет означать немедленное снижение платы для пользователя.
Чтобы сохранить баланс NFT на счете, мы могли бы использовать следующую структуру:
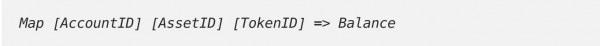
Таким образом, мы можем хранить/запрашивать баланс данного токена, принадлежащего указанному активу, для целевой учетной записи. В субстрате мы также могли бы перебирать хранилище и перечислять токены, принадлежащие учетной записи, с фиксацией актива или без нее.
Однако большой проблемой этого представления является количество операций ввода-вывода, необходимых для массовой чеканки и пакетной передачи. Например, если мы хотим создать 1 000 000 токенов в новой игре, то для этого потребуется не менее 1 000 000 записей в хранилище.
Таким же образом, пакетные передачи не будут оптимизированы, и они будут принимать одно чтение плюс две записи (одна в исходной учетной записи, а другая в целевой) за одну передачу.
Решение: Куски токенов
Один из способов уменьшить объем ввода-вывода в хранилище-это группировка объектов. В этом случае мы собираемся поместить группу токенов в единую структуру: блок.
Фрагмент-это группа последовательных токенов, которые совместно используют индекс.
Например, давайте предположим, что мы определили размер блока до 512 элементов, а индекс блока является результатом деления идентификатора токена на 512 (размер блока).
Если мы последуем предыдущему примеру, мы сократили ввод-вывод с 1 000 000 до 1 954.
Еще Один Шаг: Диапазоны
Теперь, когда мы сократили количество операций ввода-вывода, давайте попробуем уменьшить плату и пространство, выделяемое для хранения наших идентификаторов токенов. Мы собираемся использовать последовательные идентификаторы токенов для сжатия фрагментов.
Диапазон-это открытый диапазон идентификаторов токенов, например, [0,512), представляющий собой набор токенов 0,1,2,…,511. Вместо того, чтобы записывать все идентификаторы токенов внутри блока, мы будем записывать только диапазоны.
Лучший случай-это когда фрагмент заполнен, когда для его определения нам нужно всего два идентификатора. Например, фрагмент с первыми 10 токенами, такими как [0,1,2,3,4,5,6,7,8,9], будет сжат в диапазон [0,10). «Несжатая» версия фрагмента использует 10 целых чисел, в то время как для сжатой версии требуется только 2 целых числа.
В худшем случае блок содержит только нечетные или четные идентификаторы токенов, в которых нам потребуется 512 идентификаторов для представления диапазонов для 256 токенов. Например, если фрагмент содержит непоследовательные элементы, такие как [0, 2, 4, 6], тогда для его сжатого представления диапазона потребуется больше места, например { [0,1), [2,3), [4,5), [6,7) }.
Использование диапазонов увеличит сложность некоторых операций, таких как вычитание и сложение (которые используются для переводов между счетами), но эта новая сложность будет на порядок меньше, чем операции ввода-вывода.
Производительность: Звучит неплохо, но позвольте мне взглянуть на цифры.
Самое важное правило: любое улучшение ДОЛЖНО подкрепляться цифрами на контрольном уровне.
В следующей таблице показаны транзакции, на которые повлияла эта оптимизация. Остальные внешние элементы поддона были опущены, поскольку они не повлияли на производительность:
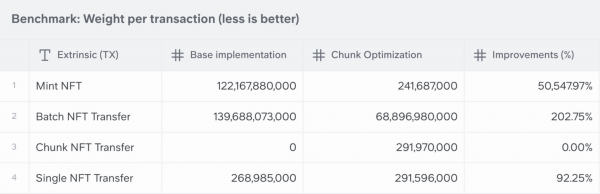
Некоторые важные вещи, которые следует подчеркнуть:
- В NFT-чеканке наблюдается впечатляющее улучшение на 50547%. В том первом черновике я смог отчеканить 120 000 000 NFT в одном блоке.
- Пакетная передача NFT показала только x2, но отклонение стандартной ошибки показывает, что мы могли бы получить более точные данные по конкретным случаям использования.
- Новый оптимизированный фрагментированный перевод NFT. Любой смарт-кошелек может воспользоваться преимуществами базовой оптимизации с помощью новых функций API. Перевод до 512 токенов на один и тот же блок будет стоить столько же, сколько один перевод.
- Ухудшение при единичных переводах составляет менее 8% при первоначальном проекте. Нам все еще нужно добавить некоторые дополнительные операции внутри этого, поэтому в будущих версиях это число будет уменьшаться.
Исходный код будет открыт в ближайшее время.
Выводы
Efinity демократизирует NFT с использованием микрозаймов и изменит правила игры для разработчиков и предприятий, которым требуется более высокая производительность при масштабных операциях.
Этот вид оптимизации может быть использован в других областях, и эти показатели все еще находятся на уровне L1, где безопасность и ликвидность поддерживаются на высоком уровне.